确保系统稳定性-支持大规模文本处理策略
随着技术的发展,大规模文本处理任务变得越来越普遍。无论是搜索引擎、数据分析工具还是机器学习应用,都需要稳定的系统支持才能高效运行。本篇将探讨如何确保系统稳定性以支持这类任务。
设计合理的架构
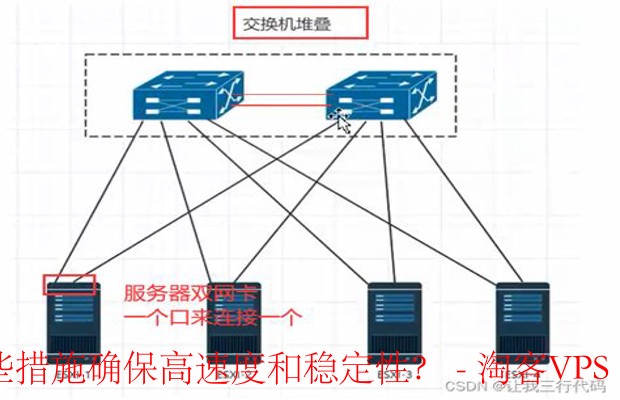
首先,构建稳定系统的基石是合理的设计架构。这包括选择合适的服务器硬件、操作系统和数据库。为了支持大规模数据处理,通常需要部署高性能的服务器和冗余的存储解决方案。同时,架构设计上应该考虑到横向扩展的能力,以便在需求增加时能够轻松添加更多的计算资源。
负载均衡与冗余
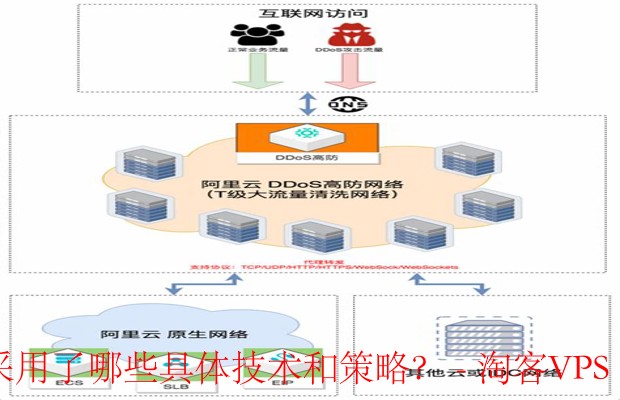
其次,引入负载均衡器和实施高可用性策略是非常重要的。通过负载均衡器,可以将请求均匀分布到多个服务器上,避免单点故障。此外,还需要确保系统中的各个组件都有备份,这样即使某个组件出现故障,整个系统仍然可以正常工作。
自动化监控与报警
为了及时发现并解决问题,需要建立一套完整的监控系统。这包括对系统性能指标、错误日志以及网络流量的实时监控。当检测到异常情况时,自动报警机制会立即通知管理员,以便迅速采取措施进行修复。
优化算法与代码

除了架构层面的考虑,还需要不断优化处理大规模文本的任务算法和代码。这可能涉及到改进数据处理流程、减少不必要的计算步骤或者采用更高效的编程语言和库。通过这些手段,不仅可以提高系统的处理速度,还能降低资源消耗,从而提升整体稳定性。
分布式计算框架
另外,利用分布式计算框架如Apache Hadoop或Spark也可以显著提高大规模文本处理的效率和稳定性。这些框架能够将任务分解成多个小任务并在多台机器上并行执行,从而大幅缩短处理时间并减轻单个节点的压力。
持续集成与测试
最后,持续集成和自动化测试也是保证系统稳定性不可或缺的一环。通过持续集成,可以在每次代码提交后自动运行一系列测试用例,确保新功能不会破坏现有功能。而自动化测试则可以帮助团队尽早发现潜在的问题,避免它们在生产环境中造成影响。