文本处理中的风险管理-策略与实践
文本处理中的风险管理是指在处理大量文本数据的过程中识别、评估和控制潜在的风险。这些风险可能来源于数据质量、隐私保护以及法律合规等方面。了解如何在文本处理中有效进行风险管理是确保项目成功的关键。
文本处理中的常见风险

在处理文本数据时,常见的风险包括但不限于数据缺失、数据错误、敏感信息泄露和法律问题。这些问题不仅会降低数据的质量,还可能导致严重的法律后果。因此,有效的风险管理对于保证项目的顺利进行至关重要。
数据清洗的重要性
数据清洗是文本处理的第一步,也是最为重要的一步。通过数据清洗,可以去除重复的数据、纠正错误的信息以及填充缺失值。这不仅能提高数据质量,还能为后续的文本分析提供可靠的基础。
采用合适的文本分析工具
选择合适的文本分析工具是另一个关键点。市场上有许多优秀的文本分析软件,它们可以帮助我们更高效地处理和分析文本数据。例如,使用Python的Pandas库进行数据处理,或者使用NLTK和Spacy进行自然语言处理,都是不错的选择。选择适合自己的工具,可以大大提高工作效率。
加强隐私保护措施
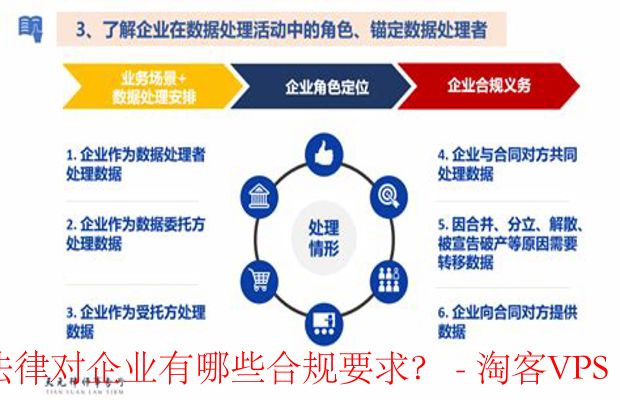
随着数据安全和隐私保护意识的增强,加强隐私保护措施变得越来越重要。在处理包含敏感信息的文本数据时,必须采取严格的保护措施,如数据脱敏、加密存储等。同时,还需要遵守相关的法律法规,确保数据处理过程合法合规。
建立全面的风险管理体系
最后,建立一个全面的风险管理体系是必不可少的。这包括对潜在风险的识别、评估以及应对策略的制定。定期进行风险评估,并根据实际情况调整风险管理策略,能够有效地预防和控制风险。
综上所述,在文本处理中有效进行风险管理需要从多个方面入手,包括数据清洗、选择合适的工具、加强隐私保护以及建立全面的风险管理体系。只有这样,才能确保项目的顺利进行,避免不必要的损失。