多语言处理与长文本解析 - 文本处理服务的挑战与解决方案
文本处理服务的多语言能力
随着全球化的发展,文本处理服务的多语言能力变得至关重要。想象一下,一个用户需要翻译一篇关于科技发展的文章,从英语转为中文、法语、西班牙语等多种语言。现代文本处理服务能够通过自然语言处理(NLP)技术,快速识别输入语言,并进行准确翻译。
除了基本的翻译功能,文本处理服务还需考虑到文化差异、语境和行业术语的适应性。因此,利用机器学习算法,不断优化翻译质量和准确性,成为行业的重要趋势。比如,某些服务还可以提供实时翻译和多语言支持,使得用户在不同语言环境下都能流畅交流。
应对长文本处理的挑战
长文本处理同样是文本处理服务面临的一大挑战。想要处理一篇数千字的学术论文或小说,如何确保信息的完整性、逻辑清晰度和内容的连贯性?文本处理服务通常会采用分段处理和摘要生成技术。通过将长文本拆分为多个小段,系统可以逐段分析并处理,最终整合出一个完整而清晰的结果。
此外,长文本还可能包含复杂的结构,比如章节、段落、引用等。为此,现代文本处理服务通过标记语言(如HTML或Markdown)来保持文本的结构性。这不仅有助于信息的整理,也为用户提供了更好的阅读体验。
多种文件格式的输入处理

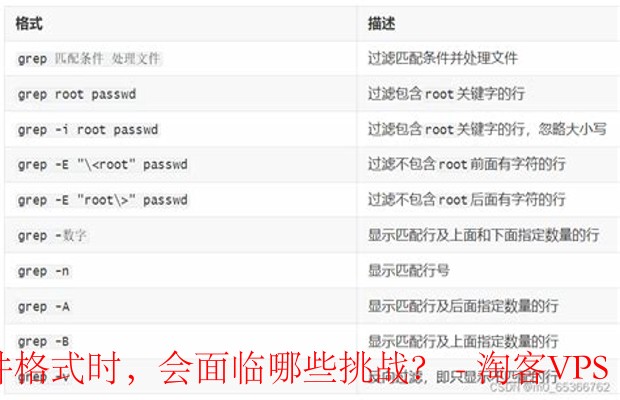
在如今的数字化时代,各种文件格式层出不穷,比如PDF、Word、Excel、TXT等。文本处理服务需要能够灵活应对不同格式的输入,以确保用户能够无缝访问和处理他们的数据。
例如,处理PDF文件时,文本处理服务需要具备OCR(光学字符识别)技术,以提取文本并进行后续分析。而对于Word或Excel格式,则需要解析其内部结构,以便用户可以直接在原有格式中进行编辑和处理。通过这种文件格式兼容性,用户能够更方便地进行信息的获取和操作。
总结与展望
综合来看,文本处理服务在多语言能力、长文本处理和多种文件格式输入方面的表现,直接影响了用户体验和工作效率。随着AI技术和机器学习的进步,未来我们可以期待这些服务将更智能化、自动化,为用户提供更加优质和便捷的文本处理体验。
因此,无论是企业还是个人用户,在选择文本处理服务时,需重视其多语言处理能力、长文本的处理效果以及对于多种文件格式的兼容性。这些因素将直接影响到文本处理的效率和准确性。