高效提取关键信息 - 多语言文本摘要技巧
在信息爆炸的时代,我们常常面对大量的长文本,如何快速从中提取出关键信息成为一个重要课题。文本摘要功能可以帮助我们解决这个问题,同时具备多语言处理能力更是让我们能够跨越语言障碍,获取全球的信息。
文本摘要的基本概念
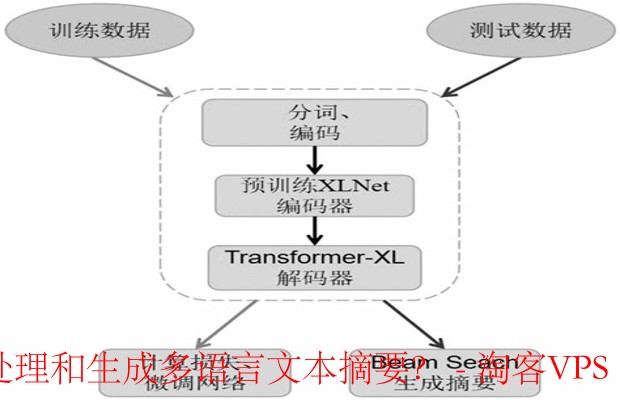
简单来说,文本摘要就是将长文本浓缩成简洁的版本,保留最重要的信息。它不仅可以帮助我们节省时间,还能提高信息的获取效率。文本摘要主要分为两种方法:提取式摘要和生成式摘要。
提取式摘要
提取式摘要通过识别文本中的关键信息,直接从原文中提取句子或短语。这种方法通常依赖于关键字提取、句子排名等技术,比如 TF-IDF(词频-逆文档频率)和文本相似度计算。
生成式摘要
相较于提取式,生成式摘要则是通过模型理解文本的整体内容,生成新的句子来表达原文信息。这要求模型具备较强的语言理解和生成能力,常用的技术包括自然语言处理(NLP)和深度学习。
多语言处理能力的重要性

在全球化的背景下,处理多种语言的文本摘要功能显得尤为重要。无论是商业文件、研究文章还是社交媒体内容,能够快速理解和提取外语中的关键信息都是一项重要技能。
多语言文本处理的挑战
每种语言都有其独特的语法、词汇和文化背景,这给文本摘要带来了挑战。例如,某些语言可能会有更加复杂的表达方式,或者特定的短语在不同语境中的含义会有所不同。因此,跨语言的信息提取需要更为灵活的算法和模型。
如何高效提取关键信息
以下是一些实用的技巧,帮助你在文本摘要功能中更高效地提取长文本的关键信息,同时保持多语言处理能力。
使用先进的NLP技术
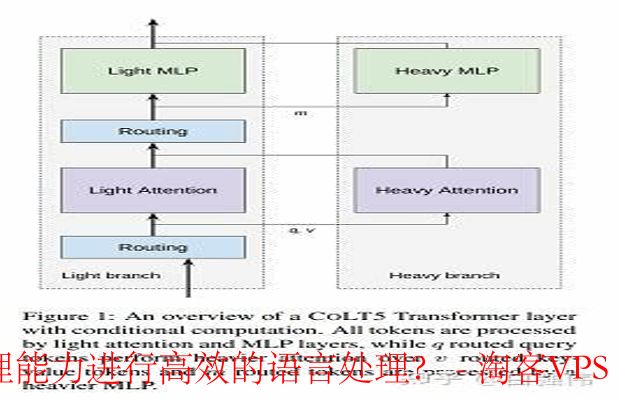
利用先进的自然语言处理技术,比如 BERT、GPT和 Transformer 模型,可以显著提高文本理解能力。这些模型能够捕捉到文本中的上下文信息,从而更有效地进行信息提取和生成。
多语言模型的训练
为了提升多语言处理能力,可以使用多语言预训练模型,如 mBERT 和 XLM-R。这些模型在多种语言的文本上进行训练,能够理解和生成不同语言的文本摘要。
强化学习与人机交互
通过引入强化学习机制,模型可以不断优化自身的文本摘要能力。人机交互环节也非常重要,可以通过用户反馈来改进摘要的质量和准确性。
实用工具与平台推荐
市面上有许多工具和平台可以帮助你实现高效的文本摘要功能,以下是一些推荐:
- Google Cloud Natural Language API - 提供强大的文本分析和摘要功能。
- OpenAI API - 可以用来生成高质量的文本摘要。
- Sumy - 一款开源的文本摘要工具,支持多种算法。
总结
高效提取长文本中的关键信息并保持多语言处理能力,是一个复杂但值得追求的目标。通过利用先进的 NLP 技术、多语言模型和人机交互,我们可以不断提高文本摘要的质量和效率。希望这些技巧能帮助你在这个信息丰富的时代,轻松获取所需的信息。