高效文本处理系统构建指南-优化存储与资源分配策略
为什么需要优化?
随着互联网信息爆炸式增长,对于能够高效处理大量文本数据的需求也日益增加。一个好的文本处理系统不仅要速度快、准确性高,还要能够在成本效益方面表现出色。这就要求我们在设计时特别关注数据存储方式以及计算资源的有效利用。
数据存储策略

合理的数据存储是确保高性能的第一步。考虑到不同类型的数据(如结构化、非结构化)及其访问模式,我们可以采取以下几种方法:
- 选择合适数据库类型:根据实际需求决定使用关系型还是NoSQL数据库。例如,如果应用场景涉及到复杂的事务操作,则可能更适合关系型数据库;而对于读写性能要求极高的场景,则可以考虑NoSQL解决方案。
- 压缩算法应用:对存储的数据进行适当的压缩不仅可以节省空间,还能加快传输速度。不过需要注意的是,过度压缩可能会导致CPU负载增加,因此需要找到一个平衡点。
- 分片技术:将大型数据集拆分成多个较小的部分,并分散到不同的服务器上存储,这样可以在查询时并行执行,从而大幅提高效率。
资源管理技巧
除了优化数据存储之外,合理调配计算资源同样重要。这里有几个小建议:
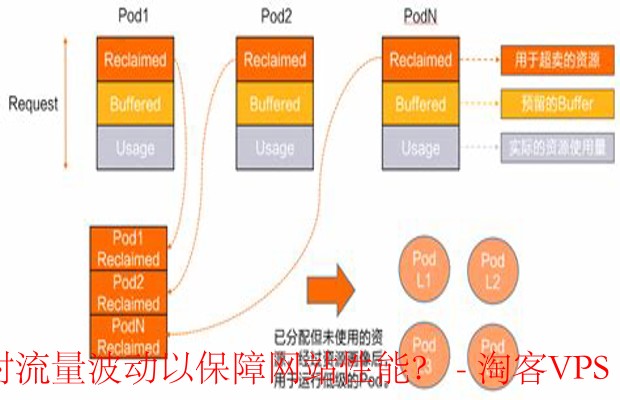
- 弹性伸缩:利用云服务提供的自动扩缩容功能,根据实际工作负载动态调整实例数量,既保证了高峰期的服务质量,又避免了资源浪费。
- 异步任务队列:将耗时较长的任务放入后台执行,并通过消息队列机制实现解耦,使得前端请求可以更快得到响应。
- 负载均衡:通过部署多台服务器并采用负载均衡器分发请求,不仅提高了系统的可用性,还增强了处理能力。
综上所述,通过对数据存储方案的精心设计以及灵活运用各种资源调度策略,我们可以构建出一个既能应对海量文本处理挑战又能保持良好用户体验的文本处理系统。当然,这只是一个大致框架,在具体实施过程中还需要结合项目特点做出相应调整。