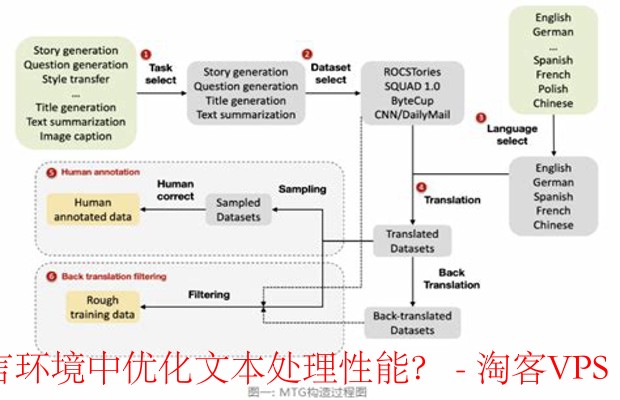
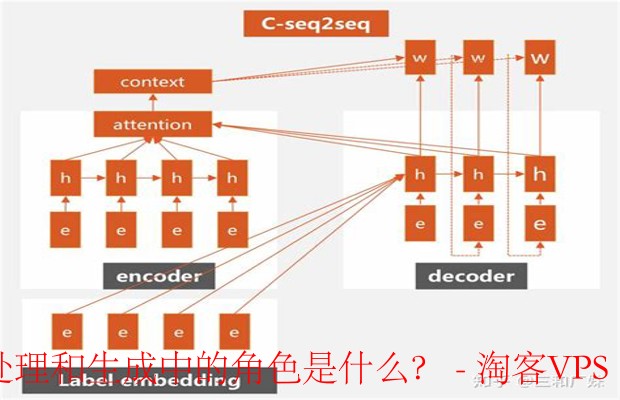
多语言文本处理的挑战 - 理解与应对策略
在当今这个全球化的时代,文本处理工具的使用变得越来越普遍,尤其是在处理多语言文本时。随着互联网的迅猛发展,来自世界各地的用户都在用不同的语言进行交流,这给文本处理工具带来了不少挑战。本文将深入探讨这些挑战,帮助大家更好地理解多语言文本处理的复杂性。
多语言文本处理的复杂性
首先,处理多语言文本的一个主要挑战是语言的多样性。全球有超过7000种语言,它们在语法、词汇、语音等方面都有显著差异。这意味着文本处理工具需要能够理解和解析这些不同的语言特征。
语言特性差异
比如,某些语言是表意文字(如汉字),而其他语言则是拼音文字(如英语)。这就要求文本处理工具在设计时考虑到这些差异,以确保能够有效地处理各种语言的文本。例如,中文的词汇结构和语法规则与英文截然不同,这对于文本分析工具来说,构成了不小的挑战。
翻译的准确性与上下文理解
另一个重要的挑战是翻译的准确性。文本处理工具通常需要将一种语言翻译成另一种语言,而这不仅仅是字对字的翻译。很多时候,语言的上下文、文化背景和习惯表达会影响翻译的质量。
上下文的重要性
例如,英语中的一些俚语在直接翻译成中文时可能没有任何意义,甚至可能引起误解。因此,优秀的文本处理工具不仅需要翻译单词,还需要能够理解语境,以保证翻译的流畅和自然。
数据集的多样性与质量
为了培养高效的文本处理工具,开发者需要大量的多语言文本数据。然而,这些数据集的多样性和质量也是一个不小的挑战。有些语言的数字化文本资源非常有限,这使得训练模型的过程变得更加复杂。
数据偏见问题
在多语言数据集中,某些语言的数据量可能远远大于其他语言,导致模型偏向于处理那些数据量丰富的语言。这种数据偏见可能会导致多语言文本处理工具在处理资源匮乏语言时的性能下降。
技术和算法的适应性

文本处理工具的技术和算法也需要适应不同语言的特性。比如,某些语言的语法结构与模型的设计不匹配,可能会导致处理效果不理想。开发者需要不断改进算法,以适应多样化的语言需求。
深度学习与语言模型
近年来,深度学习技术在自然语言处理领域取得了巨大的突破,但这些技术往往需要大量的训练数据和计算资源。处理多语言文本时,如果模型无法适应某种语言的特性,那么最终的处理结果可能会大打折扣。
跨文化交流的障碍
文本处理工具在处理多语言时,跨文化交流的障碍也是不可忽视的。不同文化背景下的语言使用习惯、表达方式都存在差异,这会影响文本的理解和处理。
文化敏感性
例如,在某些文化中,直接的表达可能被视为不礼貌,而在另一些文化中却是被认为诚实的表现。因此,文本处理工具在设计时也需要考虑到文化敏感性,以避免不必要的误解。
综上所述,文本处理工具在处理多语言文本时面临多个挑战,包括语言的多样性、翻译的准确性、数据集的质量、技术和算法的适应性,以及跨文化交流的障碍。为了提高这些工具的有效性,开发者需要在设计和实施过程中认真考虑这些因素,持续改进和优化其语义理解和语言处理能力。
随着人工智能和自然语言处理技术的不断进步,未来的文本处理工具将可能更好地应对这些挑战,帮助我们实现更高效的多语言沟通与交流。